

Do I need to know what is metadata model or schema? Not really. It is the user interface (UI) of a repository, which should control that all required metadata are included. However, a little insight into metadata model/schema can help to better structure your data. Smart metadata models naturally guide you to provide rich metadata, which facilitate data reuse. For more information: here. Here is more information what metadata are requested to acquire a digital object identifier (DOI from DataCite). Similar information (metadata) is needed to receive the Handle identifier (PID).



The Encyclopaedia Britannica defines ontology as ‘the philosophical study of being in general, or of what applies neutrally to everything that is real’. Did not it help? Google adds that ‘it is used to create a shared understanding of the data within an organization.’ Better. An ontology compartmentalizes the variables and naming of types, properties and establishes the relations between them. It is very useful for machine-readability. Machines (not only) have issues with understanding who meant what by a term ‘x’. Ontologies should define relations, vocabularies and dictionaries the terms. To learn more, look here or take a course (it is online and free). For the materials sciences and engineering (MSE) domain, the ontology with maximal in-depth insight is EMMO (Don’t look at it, it is crazily complicated). I like Meta4Ing ontology for the MSE repositories. You need WebVOWL to visualize ontologies on your computer.
Also known as glossaries. Let’s speak directly of controlled vocabularies. ‘Controlled’ means that there is an authority, which curates a vocabulary. Google says that controlled vocabularies ‘are used to ensure that data is described consistently’. Good. Together with JISC, I would add that controlled vocabularies are selected and restricted lists of terms and phrases (with guidelines for their use) providing a consistent way to describe data. Such vocabulary often defines relations between included terms and phrases. It is used to reduce ambiguity in a language of individual researchers. Each database or thematic repository usually uses its own controlled vocabularies for specific metadata fields. To learn more, visit websites such as here and here.
There are also dictionaries and taxonomies to improve general understanding of data descriptions. You know English dictionary, but let’s keep taxonomy for the future.

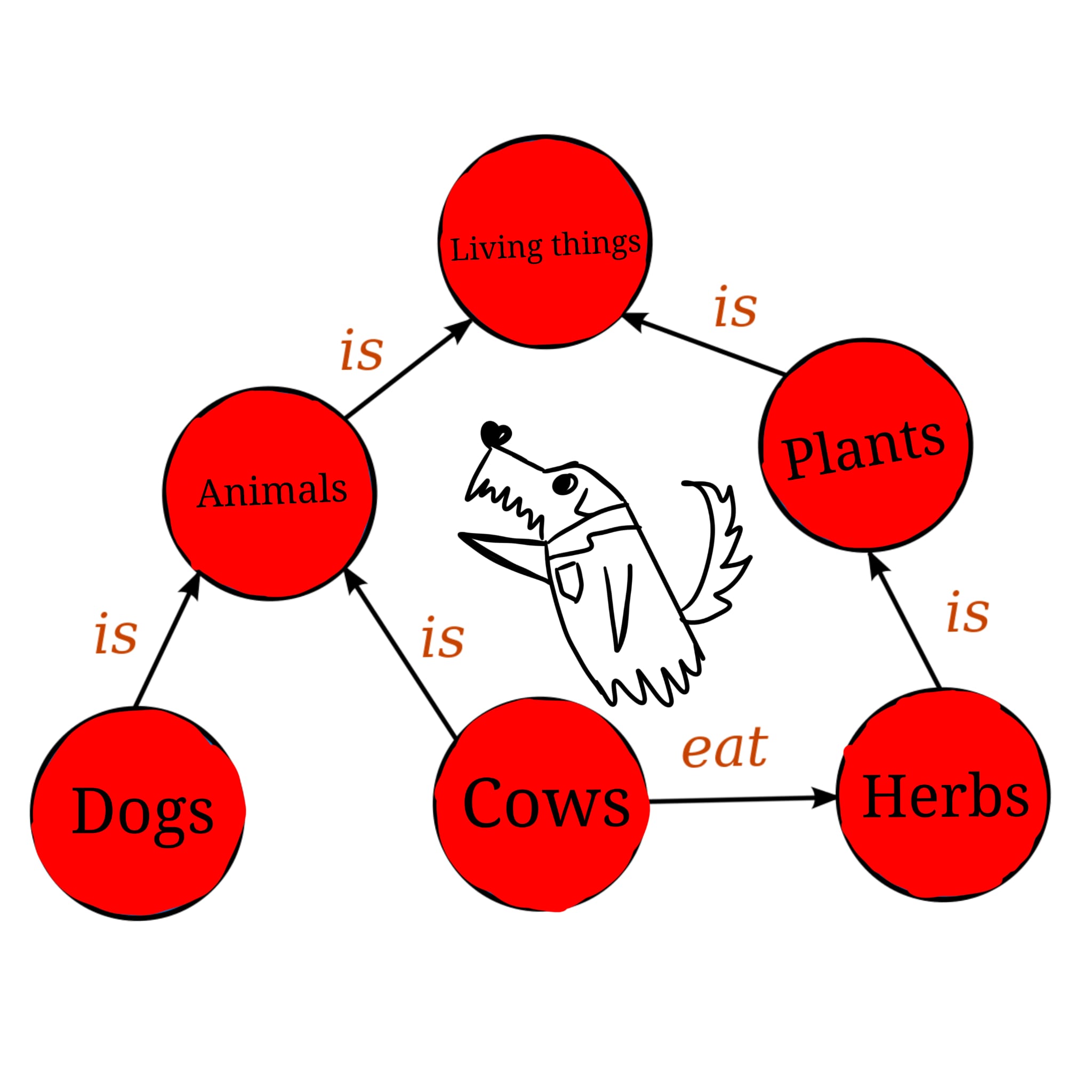

We are now touching recently popularised large language models, LLM, which are used in the artificial intelligence (AI) applications such as ChatGPT and Bard. The heart of the knowledge graph is a knowledge model. Isn’t it similar to metadata models? Only to some extent. A knowledge model is a collection of fully interlinked descriptions of entities, events, and their relations. Knowledge graphs put data in context by linking all its components using the knowledge model. The graph forms a network of relations in a database. A typical example is Wikidata. To better understand knowledge graphs, we need to learn a bit more about formal semantics and semantic web. But let’s keep that for the future. Or try on your own here or here.